


















テキスト分析の方法と手順(実践編)
~SNSのデータを使ったテキスト分析の手法をご紹介~【スタッフブログ:第4回】
更新:2021年1月22日(金)| 公開:2020年04月9日(木)| その他
当社デジタルマーケティング専門スタッフが綴る本シリーズ。
第4回目の今回は、実践的なテクニックとして役立つ場面の多い「テキスト分析」について、具体的な手順を解説します。 さまざまなデータの海から、任意のテキストを拾い集めることで知見に繋げられれば…と思うことは多いもの。 実際の操作画面とともに説明していきますので、ぜひ皆さんトライしてみてください!

こんにちは、コニカミノルタジャパンの永井です。
未曾有の状況に世の中が揺れていますが、心と身体の健康に気を配りながら今年度も頑張っていきましょう!
第4回のテーマは「テキスト分析の方法と手順」です。
営業日誌、アンケートのFA欄、クチコミ、SNSのデータなど、テキストデータからビジネスに役立つ知見を得てみましょう。
1.Twitterからテキストデータを集めてみよう
商品に関する生の声を集めるうえで、SNSは重要なデータになります。
そこで今回は、Twitterからコニカミノルタのプラネタリウムに関するつぶやきを取得し、分析してみたいと思います。その手法をご紹介いたします。
Twitter APIを用意する
まず、Twitter社からAPIを取得します。こちらにアクセスして必要事項を記入し、API Key、API secret key、Access token、Access token secretを取得します。
この申請には英作文なども必要で、通るのに1か月くらいかかるそうです。すぐにテキスト分析を試したい方、Twitter以外のテキストを分析したい方は、2.形態素解析とは? から始めて頂いても大丈夫です。こちらなら、プログラムの作成も不要になります。
Python環境を用意する
プログラミング言語Pythonを使います。Pythonを扱えるデータ分析ツールJupyter Notebookが便利です。開発環境パッケージAnacondaをインストールすると、Jupyter Notebookと一緒に、必要なライブラリがほとんど入った状態で始められます。
データを取得する
Jupyter Notebookを起動し、表の右上のNewからPython3を選択すると、次のような画面になります。
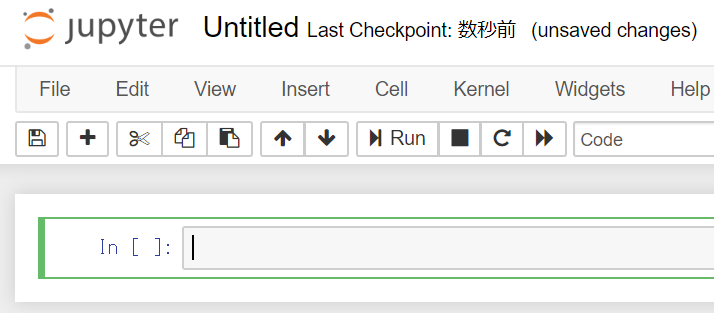
この「In[ ]:」に続く部分にコードを書き込み、Shift+Enterキーを押すと実行されます。一行ずつでも、まとめて入力してもよく、実行結果を確認しながら進められます。
Twitterから特定のキーワードを含んだつぶやきを取得するコードは、次のようになります。
#Twitterからデータを読み込むのに必要なライブラリをインストール
pip install twython
#ライブラリの読み込み
from twython import Twython
#APIの読み込み
APP_KEY = "ご自身のAPI Key "
APP_SECRET = "ご自身のAPI secret key "
OAUTH_TOKEN = "ご自身のAccess token "
OAUTH_TOKEN_SECRET = "ご自身のAccess token secret "
#twitterを開く
twitter = Twython(APP_KEY, APP_SECRET, OAUTH_TOKEN, OAUTH_TOKEN_SECRET)
#検索するキーワードを設定。コンマ区切りで複数指定可能。リツイートを除くフィルタを付けます。
keyword='プラネタリウム, コニカミノルタ, -filter:retweets'
#取得するツイート数はcountで指定。最大数は200ですが、APIの事情で全て取得できない場合もあります。
tweets = twitter.search(q=keyword, count=50)
#取得したツイートを表示 for tweet in tweets['statuses']:
print (tweet['user']['screen_name'],tweet['text'])
取得したつぶやきが表示されたでしょうか。ファイアウォールに弾かれてエラーが出ることもあるので、ご確認ください。
取得したツイートを、csvファイルに保存します。
#データフレームを扱うためのライブラリの読み込み
(Anacondaと一緒にインストールされているはずですが、もしpandasライブラリがなければ、先にpip install pandasしてください)
import pandas as pd
#現在リスト状態になっているtweetデータをデータフレームに変換
df = pd.DataFrame(tweets['statuses'])
#csvファイルに書き出し。encodingを入れないと文字化けします。
df.to_csv('tweet.csv', encoding='utf_8_sig')
csvファイルは、Jupyter Notebookの初期画面で表示されるフォルダに保存されています。開いて、確認してみてください。
データ分析おすすめ情報
2.形態素解析とは?
取得したテキストデータは、日本語で書かれています。
これが、実は大問題です。
”This is an apple.”のような英文は、単語がスペースで区切られているので、コンピュータも「入っている単語はThis、is、an、appleの四つだな」と理解できます。
しかし「これはりんごです」のような和文にはスペースが入っていないので、コンピュータは区切り位置が分からない。そのままだと、「こ、れ、は、り、ん、ご、で、す、の8単語ですか?」ということになります。
そこで、日本語が分かる人間が「これ、は、りんご、です、の4単語だよ」と教える辞書を作り、それぞれの品詞(名詞や動詞等)を判別する前処理が必要で、これを形態素解析といいます。
PythonでもJanomeライブラリなどを使えば処理可能ですが、次のテキストマイニングにそのまま移行できるので、フリーソフトKH Coder上で行います。
KH Coderをダウンロード、インストールして、開きます。
「プロジェクト>新規」で新規プロジェクトを開き、分析対象ファイルをtweet.csv、分析対象とする列をtextにしてOKを押します。
「前処理>テキストのチェック」を選択してから「テキストの自動修正」を実行して閉じます。さらに「前処理>前処理の実行」を選択すれば、形態素解析は完了。簡単です。
注意点として、KH Coderは、一般的な単語しか知りません。「ツール>抽出語>抽出語リスト」を開いてください。
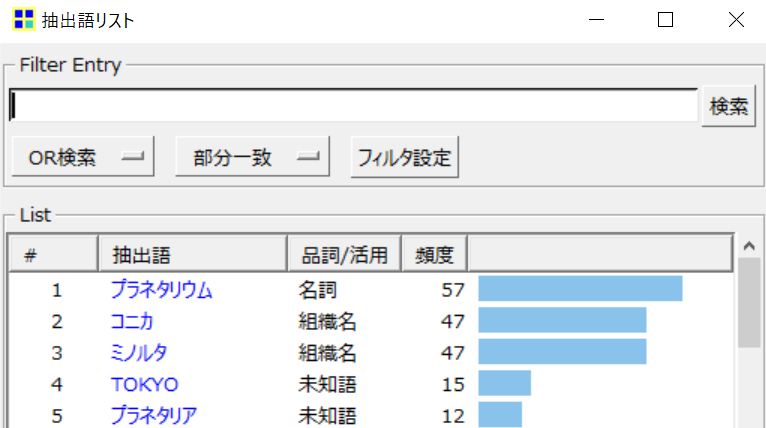
「コニカ」と「ミノルタ」が分離しています。コニカ社とミノルタ社は経営統合しているので、「コニカミノルタ」として扱ってほしい。
こういうときは「前処理>語の取捨選択」を選択し、「強制抽出する語の指定」のところに「コニカミノルタ」と書いてから、再度「前処理>前処理の実行」をすればOKです。強制抽出したい言葉が複数ある場合は、改行して書き足します。
分析に使用したくない単語がある場合は、「使用しない語の指定」のところに書きます。
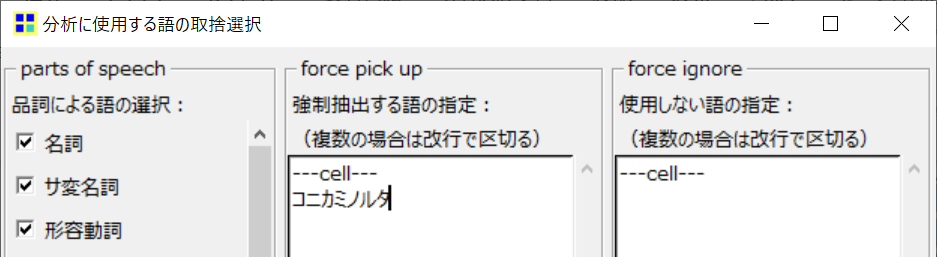
再度「ツール>抽出語>抽出語リスト」を開き、強制抽出されたか確認します。
3.テキストマイニングをやってみよう
それでは、テキストマイニングに入ります。まず、データの全体像を見てみましょう。
「ツール>抽出語>共起ネットワーク」を選んでOKをクリックすると、まとまって現れる単語が同じ色で表示されます。各単語をクリックすると、その単語がどんな文脈で使われているのか、前後を確認することもできます。
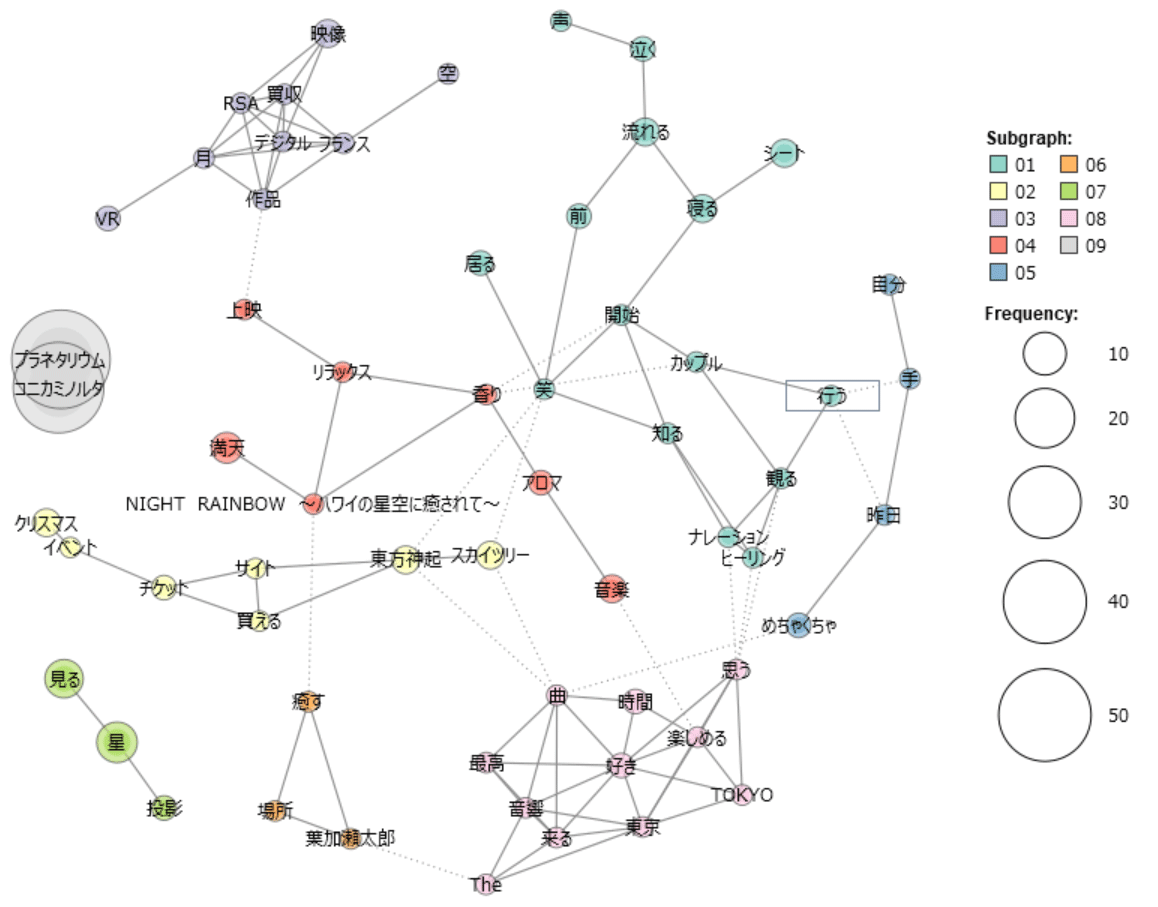
左上の青灰色(03)の塊は、2019年11月のRSA社買収の話題です。ニュースリリースと、その感想が出てきています。
中央付近のオレンジ(04)の塊は、「NIGHT RAINBOW ~ハワイの星空に癒されて~」というプログラムの感想です。こちらは、ハワイの星空に浮かぶ幻想的な夜の虹を眺めながら、ハワイをイメージした2種類のオリジナルブレンドアロマを楽しめる、癒しのプログラムです。
お客様の感想には、「リラックス」や「香り」、「アロマ」が出現しています。楽しんでいただけたようで、うれしいです!
一つの単語にフォーカスして関連語を見ることもできます。
「ツール>抽出語>関連語検索」で「直接入力」のフォームに「癒す」を入力します。「集計」を押した後、「共起ネット」をクリックすると、「癒す」に関係する単語が共起ネットワーク図になって表示されます。知りたいキーワードに対して、より詳細に関連語を把握することができます。
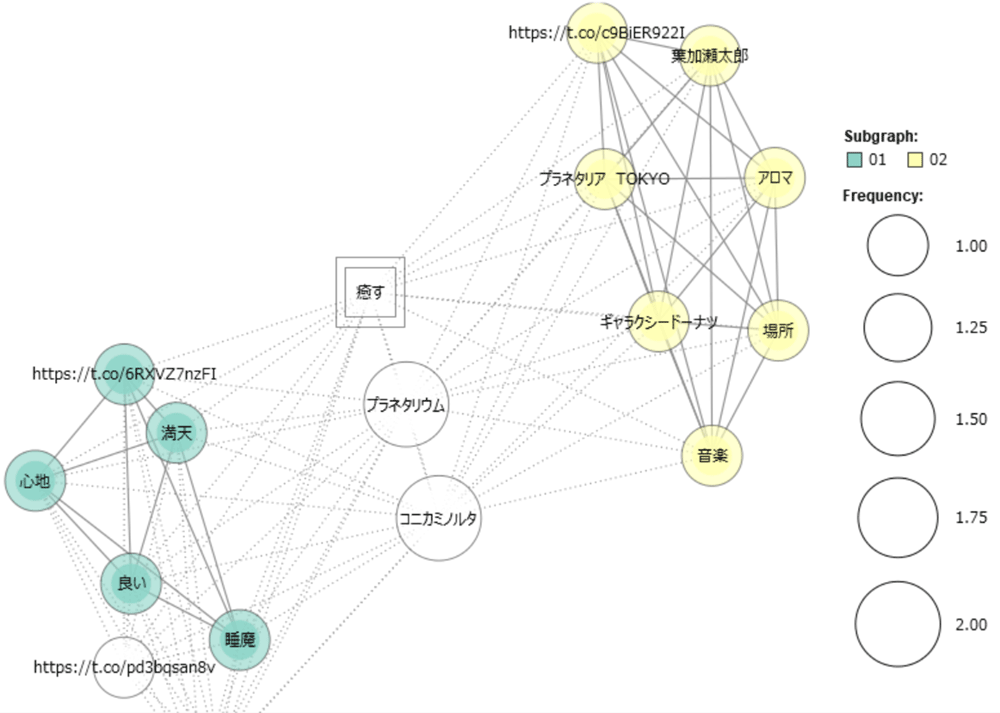
他にも、指定した単語がいつから現れるようになったかを見たり、特徴的な語を抽出したりと、さまざまな分析を行うことができます。
さて、私のブログは、今回で一区切りとなります。
本シリーズで「データ」に関する興味を少しでも高めていただくことができたでしょうか。
みなさんのお役に立てていれば、嬉しいです。
今後もデータ分析に関する情報は、不定期で発信していこうと思っています。
関連コラム


関連ソリューション
著者プロフィール

コニカミノルタジャパン株式会社
マーケティングサービス統括部
デジタルマーケティング戦略部 データサイエンティスト
永井 睦美
2019年にコニカミノルタジャパンに入社し、データ分析基盤の開発に携わる。
学生時代は、オンラインコミュニティにおける協働の特性について研究。電気通信大学データアントレプレナーフェロープログラム修了。
趣味はサイエンス雑貨集めと、歴史的建造物巡りです。毎朝ストームグラスを眺めて「よくわからん」と唸っています。
Web&デジタルマーケティングの
お悩みを一緒に解決します!



今後のセミナー開催情報をメルマガにてお送りします